Python Vs. PySpark: Which Spark API is Right for Your Data Science Project?
When it comes to working with big data, two of the most popular tools are Python and PySpark. While both can be used for data science and analytics tasks, they serve different purposes and have distinct characteristics. In this article, we'll delve into the world of Spark APIs and explore the main differences between Python and PySpark, helping you determine which one is right for your next data science project.
The lines between Python and PySpark have been increasingly blurred in recent years, with the two often being used interchangeably in data science discussions. However, this is not entirely accurate. While both can be used for big data analytics, they have different origins, design philosophies, and use cases. Python, with its vast array of libraries and tools, has long been a favorite among data scientists. PySpark, on the other hand, is a Spark API designed specifically for big data processing, built on top of the Apache Spark framework.
The Rise of PySpark
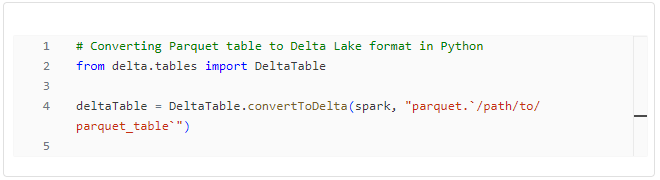
PySpark has gained significant traction in recent years, especially in the realm of big data analytics. Developed by Databricks, a leading provider of enterprise data collaboration platforms, PySpark is designed to leverage the power of Apache Spark, a unified analytics engine for large-scale data processing. With its ability to handle complex data pipelines, PySpark has become a go-to choice for many data scientists working with massive datasets.
"As PySpark continues to evolve, we're seeing more and more data scientists turn to it for their big data needs," says Matei Zaharia, co-founder and CEO of Databricks. "PySpark's ease of use, high performance, and seamless integration with other tools make it an attractive choice for data science teams."
Python: The Versatile Choice
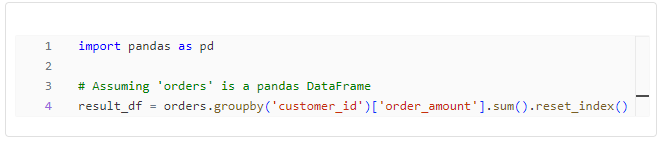
Python, on the other hand, has been a staple in the data science community for decades. With its vast array of libraries, including NumPy, pandas, and scikit-learn, Python has become the language of choice for many data scientists. Its simplicity, flexibility, and extensive community support make it an ideal choice for a wide range of data science tasks, from data wrangling to machine learning.
"I've been using Python for data science for years, and I love its simplicity and ease of use," says Rachel Thomas, data scientist at a leading fintech company. "While PySpark has its advantages, I still find myself reaching for Python for most of my projects."
Key Differences: Performance, Ease of Use, and Integration
So, what sets Python and PySpark apart? Here are some key differences:
* **Performance:** PySpark is built on top of Apache Spark, which provides a significant performance boost compared to traditional Python. This makes it an ideal choice for large-scale data processing tasks.
* **Ease of Use:** Python, with its extensive libraries and tools, is generally easier to use than PySpark, especially for smaller-scale projects. However, PySpark's syntax and API are designed to be more intuitive for big data processing, making it a better choice for complex data pipelines.
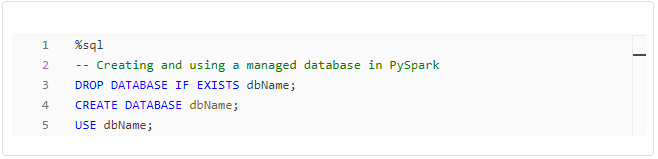
* **Integration:** PySpark seamlessly integrates with other tools and frameworks, including Hadoop, Hive, and Mesos. This makes it an attractive choice for data science teams working with existing infrastructure.
Use Cases: When to Choose Python and When to Choose PySpark
So, when should you choose Python, and when should you choose PySpark? Here are some use cases to consider:
* **Small-Scale Projects:** Python is a great choice for small-scale data science projects, such as data wrangling, visualization, and machine learning. Its ease of use and extensive libraries make it an ideal choice for these tasks.
* **Large-Scale Data Processing:** PySpark is a better choice for large-scale data processing tasks, such as data engineering, data warehousing, and big data analytics. Its performance, ease of use, and integration with other tools make it an attractive choice for these tasks.
* **Existing Infrastructure:** If you're working with existing infrastructure, such as Hadoop or Hive, PySpark is a better choice. Its seamless integration with these tools makes it a natural fit for data science teams working with existing infrastructure.
Conclusion
In conclusion, while both Python and PySpark can be used for data science and analytics tasks, they serve different purposes and have distinct characteristics. Python is a versatile choice for small-scale data science projects, while PySpark is a better choice for large-scale data processing tasks and existing infrastructure. By understanding the key differences between these two tools, you can make an informed decision and choose the right tool for your next data science project.